Door Mischa Masthoff, gepubliceerd op 13-05-2021
Stel je voor. Je hebt een webshop in vazen. Je verkoopt er twee aan dezelfde klant. Je gebruikt voor alletwee een andere pakketbezorger. Gewoon, omdat het kan. Bezorger A haalt de vaas bij je op, brengt hem naar het distributiecentrum, sorteert hem en bezorgt hem bij je klant. Bezorger B haalt de vaas bij je op, brengt hem naar het distributiecentrum, sorteert hem, gaat op weg naar de klant, rijdt terug naar het distributiecentrum, sorteert hem en bezorgt de vaas bij je klant. Vanuit het klassieke Process Mining-denken neem je de volgende keer weer bezorger A. Toch kan de praktijk genuanceerder zijn...
Hoe ziet de vaas eruit?
Wat nou als de klant aan een onverharde weg woont? Een weg met kuilen en hobbels. Bij bezorger A, die het ideale process heeft doorlopen, blijkt de vaas bij bezorging stuk te zijn. Bezorger B zag het pad, is teruggereden naar het distributiecentrum om de vaas in een extra laag noppenfolie te verpakken en bezorgt de vaas onbeschadigd. Bezorger B heeft geen ideaal proces, maar wel een optimale uitkomst.
Natuurlijk kun je zeggen dat vanuit het klassieke Process Mining geredeneerd ook bezorger A geen optimaal proces volgt. Verderop in zijn proces zit namelijk op enig moment een klacht, schadeafhandeling of een nieuwe zending.
Toch durven wij de stelling aan dat in de administratieve dienstverlening Process Mining onvoldoende aandacht heeft voor de kwaliteit van de output van het proces. Om dat goed uit te kunnen leggen, moeten we eerst stilstaan bij de basistheorie achter Process Mining.
Waste indicatoren uit de LEAN methodiek
Het gaat voor dit artikel te ver om uitgebreid in te gaan op alle theorie achter Process Mining, maar het is wel goed als je een paar basisbegrippen kent. Let op: We beperken ons in dit artikel tot de processen uit de administratieve dienstverlening.
Met Process Mining zoek je naar patronen in de logbestanden van je IT-systeem. Van een aanvraag wordt bijgehouden in welke stap die zich op dit moment bevindt, in welke stap hij daarvoor zat, wat de vervolgstap is en hoelang de aanvraag zich in iedere stap bevindt.
Een ideale aanvraag loopt langs een zogenaamde ‘happy flow’. Dat betekent dat de aanvraag de vooraf ontworpen ideale route aflegt. Er treedt met andere woorden geen ‘verspilling’ (of: ‘waste’) op.
Vanuit de LEAN-methodiek worden verschillende oorzaken van verspilling gedefinieerd.
Informatie overstroom: Wanneer er te veel informatie is gegenereerd, is het verspilling van moeite en beweging. Voorbeelden zijn het verzenden van te veel kopieën of e-mails en het opslaan van documenten op verschillende plekken.
Wachten: Als er wordt gewacht op een activiteit die later dan de gestelde norm wordt geleverd.
Extra verwerking: Wanneer een stap niet ‘the first time right’ is.
Beweging: Onnodige beweging van een workflow; de beweging voegt geen waarde toe. Een voorbeeld is als een medewerker informatie niet automatisch uit kan wisselen en moet blijven wisselen tussen systemen.
Variabiliteit in doorlooptijden: Bij gebrek aan standaardisatie in routine processen, kan het voorkomen dat variabiliteit in doorloop- en wachttijden zich voordoet.
Onderbenutting van de talenten van mensen en capaciteiten van systemen: Wanneer menselijk potentieel onbenut blijft, leidt dit tot verlies van motivatie en creativiteit van medewerkers. Dit geldt ook voor IT-systemen. Systemen worden niet gebruikt door gebrek aan training of communicatie, dit resulteert in gemiste kansen voor efficiëntere activiteiten
Defecte informatie: Ontbrekende of foute informatie in een proces of fouten in systemen.
Het bovenstaande proberen we hieronder simpel uit te leggen met een plaatje.

De gescheiden werelden van proces en output
De crux is dat bijna alle categorieën hierboven niks met de kwaliteit van je output te maken hebben. Ze kijken naar de efficiëntie van je proces. Anders gezegd: was de bezorging snel en niet: is de vaas nog heel? Er is een uitzondering en dat is de categorie ‘defecte informatie’.
Het probleem is dat ‘defecte informatie’ in Process Mining de verspilling is die in het proces wordt opgemerkt. Op het moment dat een aanvraag terug wordt gestuurd naar een vorige stap met bijvoorbeeld een ‘change-’, ‘reject-’ of ‘edit-status’, dan wordt dit weggeschreven in de logbestanden en wordt de verspilling zichtbaar bij reguliere Process Mining.
De paradox is dat in processen die op efficiëntie gericht zijn, kwaliteitsinspecties in de praktijk steekproefsgewijs of marginaal worden uitgevoerd. Bijvoorbeeld: is het BSN-nummer ingevuld en niet klopt het BSN-nummer?
Het gevolg daarvan is dat verborgen fouten de uitkomsten van je Process Mining analyse flink kunnen vertekenen. Als een organisatie vervolgens haar processen of werkwijze aanpast op basis van die analyse, dan is het risico dat de organisatie wel efficiënter gaat werken, maar niet beter. In het ergste geval gaan dingen vlotter fout.
Combineren van Process Mining met Analytics
De oplossing voor dit probleem is het combineren van Process Mining met Analytics. Met Analytics bedoelen we in dit geval het geautomatiseerd (integraal) scannen van je data op fouten en risico’s.
Een voorbeeld. Met behulp van een zogenaamde VIES-check kun je geautomatiseerd controleren of een BTW-nummer correct is of niet. Slimme software kan ook controleren of bijvoorbeeld de juiste BTW-codes gebruikt zijn, of de juiste BTW-percentages in rekening gebracht zijn, et cetera. Omdat dat geautomatiseerd kan, kan het ook integraal en continu. Op het moment dat je die informatie combineert met de informatie uit je logbestanden, dan wordt niet alleen zichtbaar hoe (in dit geval) het facturatieproces is doorlopen, maar ook welke varianten in een proces leiden tot meer of minder fouten in je output.
Het is niet ondenkbaar dat de proces-variant, die leidt tot de minste fouten, niet het ogenschijnlijk meest efficiëntie proces is.
De Process Output Matrix
In dit soort gevallen – de gevallen waarin het leven niet zwart wit is – maken duurbetaalde adviseurs graag een matrix. Hoewel we tegenwoordig data-analyses verkopen voor de prijs van een kop koffie (en daarmee nauwelijks duurbetaald zijn te noemen), hebben we ‘for old times’ sake’ er toch maar een bedacht. Best een goede, al zeggen we het zelf. We noemen hem: de Process Output Matrix.
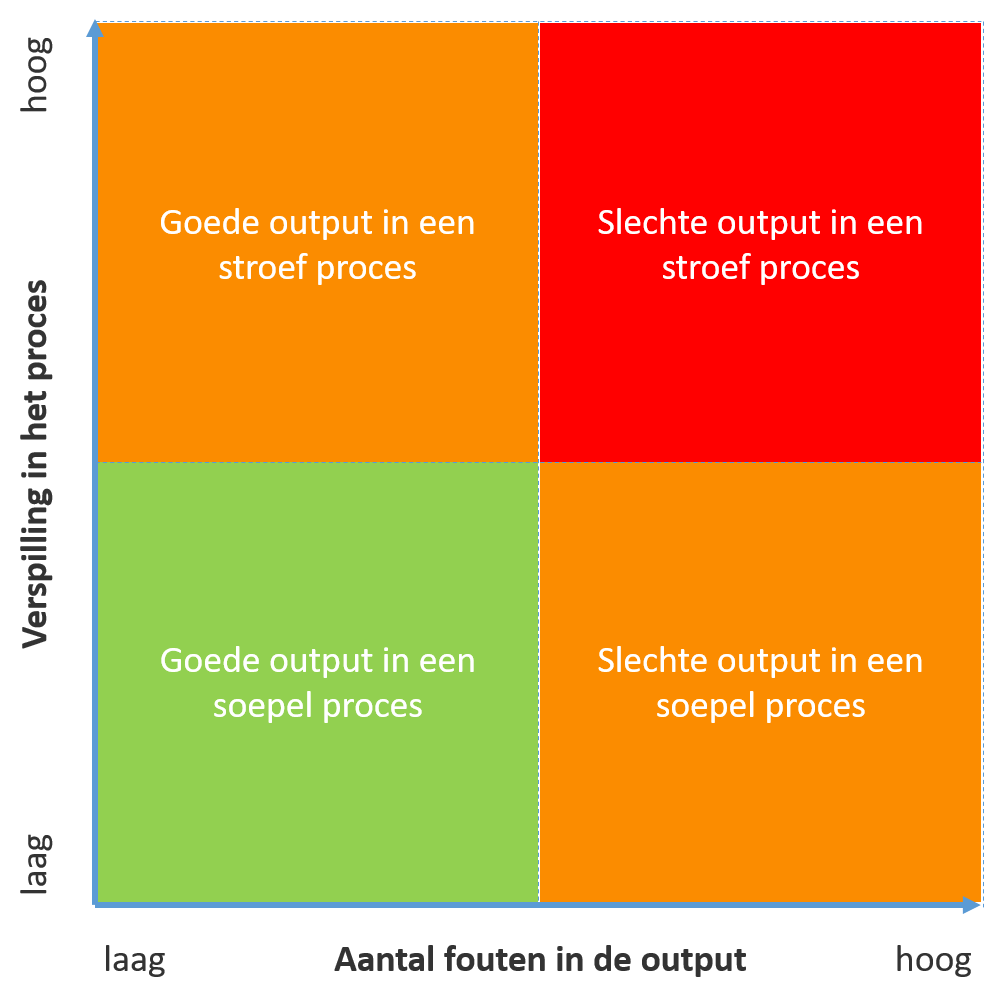
Op de horizontale as hebben we het aantal fouten in de output. Op de verticale as hebben we de verspilling in het proces. Linksonder zit de ideale situatie. Goede output in een proces zonder verspilling. Rechtsboven zit je in de problemen. Fouten in de output in een proces vol verspilling. In de resterende twee vlakken wordt het interessant. Wat is beter? (Veel) fouten in de output in een proces zonder verspilling (linksboven)? Of toch liever: goede output in een suboptimaal proces? Er vanuit gaande dat de output in je proces waarde toevoegt aan je organisatie en daarmee prevaleert boven het hebben van zo laag mogelijke kosten, zou je, naar onze mening, altijd moeten kiezen voor goede output in een suboptimaal proces. Toch ligt de focus van reguliere Process Mining op het optimaliseren van het proces, zonder (gedegen) te kijken naar de kwaliteit van je output. En dat is zonde. Want uiteindelijk heeft de klant van je webshop in vazen liever een onbeschadigde vaas die een dag te laat is, dan een kapotte vaas binnen 24 uur.
In control met onze oplossingen
We hebben verschillende producten om met algoritmes in control te komen. Om datagedreven te gaan werken en om data slim te gebruiken om continu te verbeteren.
GRATIS
FLEX
EXPERT
ENTERPRISE